UI-TARS
4.4 加强复杂任务推理能力
-
ActRe
对于已经产生的轨迹 \((o_1,a_1,\cdots,o_n,a_n)\) 补上思考 \(t_n\)
具体地, 对 VLM 做 prompt
\[t_n=\text{VLM}(\text{instruction}, (o_1,t_1,a_1), \cdots, o_n,a_n)\] -
bootstrapping approach
上面产生的思考可能与 \(a_n\) 关联性不强, 因为只是根据之前 \(n-1\) 轮的动作, 观察和思考, 加上 \(n\) 轮的动作观察总结得到第 \(n\) 轮的思考, 缺少了从前 \(n-1\) 轮推理决策出 \(a_n\) 的过程
所以不参考 \(a_n\), 而是同时产生动作思考对
采样 \((\hat t_{n_i}, \hat a_{n_i})\), 并选择 \(\hat a_{n_i}=a_n\) 的那一对
这样的思考 \(t_n\) 可以是模型学习到更好的决策过程
\[(\hat t_{n_i}, \hat a_{n_i})_{i=1}^{\text{max-try} }=\text{UI-TARS}_{\text{early} }(\text{instruction}, (o_1,t_1,a_1), \cdots, o_n)\]\[\text{select }(\hat t_{n_i}, \hat a_{n_i})\text{ where }\hat a_{n_i}=a_n\]
4.5
-
Online
采样出若干个行动轨迹, 然后基于规则, VLM, 人等筛选出一条好的轨迹, 用他去微调模型
-
Reflect
让 annotators 标注出出错的操作, 并提供下一步纠正的 action
-
DPO
用强化学习让 Agent 对于最优的操作产生偏好 (相比于次优的操作)
定义一个 reawrd 函数为 \(r_\theta(s_\tau,a_\tau)\), 代表想要在状态 \(s_\tau\) 选择动作 \(a_\tau\) 的渴望程度
定义对于行动 \(a_{\tau}',a_{\tau}\) 的偏好似然为
\[P_\theta(a_\tau'\succ a_\tau\mid s_\tau)=\frac{\exp{r_\theta(s_\tau,a_\tau')} }{\exp{r_\theta(s_\tau,a_\tau')}+\exp{r_\theta(s_\tau,a_\tau)} }\]那么用 DPO 最小化这个损失函数的期望:
\[\mathcal{L}_{\text{DPO} }(\theta)=-\mathbb E_{\tau}[\log \sigma(\beta\log\frac{\pi_\theta(a_\tau'|s_\tau)}{\pi_{\text{SFT} }(a_\tau'|s_\tau)}-\beta\log\frac{\pi_\theta(a_\tau|s_\tau)}{\pi_{\text{SFT} }(a_\tau|s_\tau)})]\]这样可以最大化提高正确动作的似然
AppAgent
-
exploration by autonomous interactions
将 UI element 的功能与作用通过分析截图的方式以文字形式写入一个文件
通过过去的文件和现在的观察来更新文件
通过使用 LLM 现有的知识加深理解
-
exploration by watching demos
同时还可以让人类演示, 让 LLM 学习人类的动作
-
deployment
每一步截图, 根据截图和之前的文件做出思考与行动, 同时将思考加入下一轮的提示词, 作为记忆
CogAgent
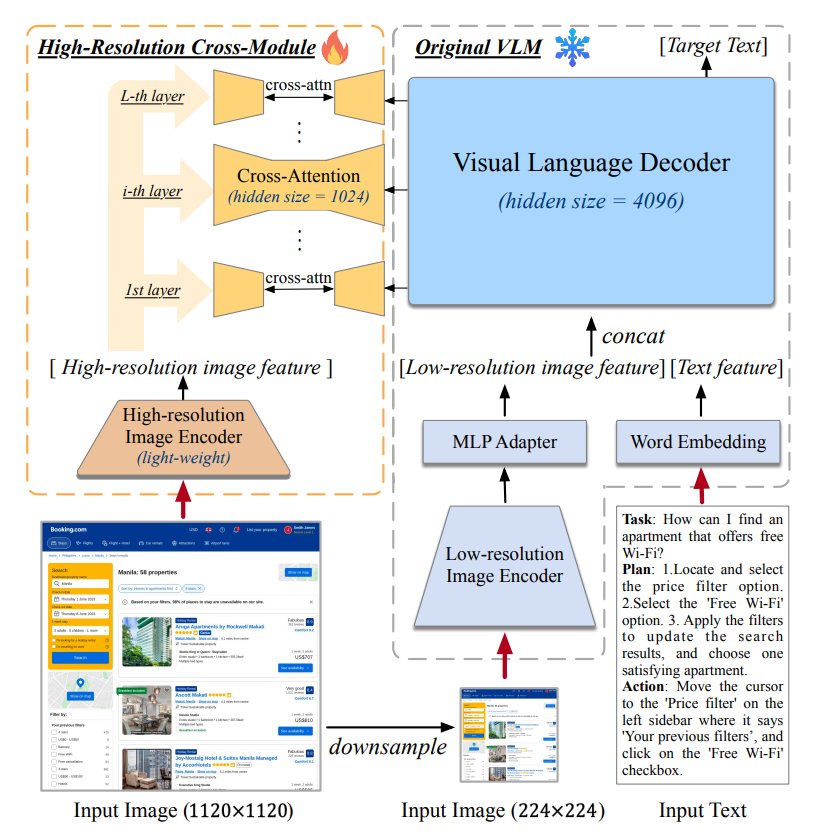
High-Resolution Cross-Module
在原本的 VLM 基础上加入了一个高分辨率的交叉注意力模块, 为了解决低分辨率下文字信息失真的情况
处理文字信息需要的 hidden size 一般更小
同时使用一个轻量化的 image encoder (CLIP)
定义几个常量:
\(L_{I_{lo}}, L_{I_{hi}}, L_T\) 表示低分辨率, 高分辨率和文字序列的长度
\(D_{dec}, D_{hi}\) 表示 右边 VLM Decoder 和左边 Image Encoder 的维数
\(B\) 是 batch size
\(X_{in_i}\in \mathbb R^{B\times(L_{I_{lo}}+L_T)\times D_{dec}}\) 是右边 VLLM 的 transformer 输入
\(X_{hi}\in\mathbb R^{B\times(L_{I_{hi}})}\times D_{hi}\) 表示 左边 Image Encoder 的输出
那么有每一层的迭代公式:
这里面可以看出, 由于残余网络加的是 \(X_i'\), 所以 \(X_i'\) 是 Query, \(X_{hi}\) 是 Key, Value, 表示计算了文字 + 低分辨率信息与高分辨率信息的相关程度, 并把加权求和后的高分辨率信息与文字 + 低分辨率残余信息相加后输出作为下一层输入
这样高分辨率信息作为了与文字 + 低分辨率信息相关的补充流入下一层
参考